Key Concepts: Events, Pipeline, Handlers¶
Overall, the NA64SW project is a trade-off between some advance programming concepts offering numerous benefits at one side and a minimalistic easy-to-use framework providing an extensible and flexible environment for data analysis.
Despite involving these concepts into collective work may cost a significant effort at the beginning due to presence of advanced techniques, the rest of the time these design, if followed, will not cause exponential grow of complexity as the analysis will elaborate.
Albeit the art of data analysis itself can not be encompassed by any single rule of thumb, there are some widely used patterns that may naturally be expressed with modern programming languages.
One of such patterns is a so-called “pipeline” pattern) wich offers an flexible, extensible and transparent way to organize data-handling routines with large amount of reentrant code.
Pipeline is built with an arranged set of entities (called “handlers” or “processors”). First, the single event data is acquired from some source – the stored file, running experimental DAQ, network sockets, etc. Then it is “propagated” through the pipeline by sequentially invoking each handler procedure with the event data provided as an argument. Handlers can transform the data by applying corrections, adding some subsidiary information and so on.
Each handler represents (or at least has to represent) a single procedure with one clear purpose. Handlers are opaque in the sense the pipeline pattern itself clamps only input and output data formats of the procedure, but the implementation itself is free from restrictions – handlers may transform the input data, generate plots, accumulate sums, apply calibrations and do whatever usual data analysis procedure does.
In order to arrange handler in a pipeline, they must obey the certain unifyed contract that in software is called “interface”. From programatical point of view we have to say that individual handler must implement an interface meaning that the contract expressed as an interface, in our case fixes the input and output data formats, and each particular handler is a piece of code that defines what happens in between.
One may immediately notice a limitation of the input and output handlers data format. Indeed, this is the prominent drawback of the linear pipeline approach: sometimes users have to introduce additional data fields to the event structure and by changing the event we do modify the contract each handler has to satisfy. So the fundamental limitation of the implementing data processing this way (in terms of handlers-in-a-pipeline) must be expressed as “whether my processing will require as significant changes in the event data format?”
On the other hand, the benefits of the pipeline approach are:
Development of handler is typically easier than development of dedicated utilities and imply less amount of code being duplicated. Event retrieval, management of the run metadata (retrieving and applying corresponding calibrations), ROOT TFile lifecycle, configuration management, logging and many other relevant activities are the subjects of well-tested and reliable pipeline infrastructural code that has been already implemented. Handlers developer may focus solely on their subject area.
Complexity of the data treatment application increases much more gradually w.r.t dedicated utilities, due to divide’n’conquer principle of organization
By maintaining a set (a library) of handlers within the project, the developers (experimental collaboration or various maintaining teams) may provide a cumulative set of gradual updating reentrant tools with clear repsonsibility managament.
Single infrastructural code is easier to test, letting team members to focus on their own area of expertise. The only stepping stone here is to help them catch few software abstractions: the pipeline, the handler, the handler lifecycle.
Pipelining applications may cover a wide range of practical cases without re-compiling the code. By changing the configuration file one may build their own unique solutions without need od re-compiling and re-linking executable. This configuration file may be maintained manually, via shell script, via network by file share, task server and so on, providing basic facility to IPC/RPC.
Let us briefly discuss some key features of the software we propose here in this NA64SW package.
Practical Considerations¶
To develop a well-defined software system we have to impose some practical boundaries that shape the general interfacing scheme.
The single event, including the raw and reconstructed data is an atomic entity, meaning that it does not depend on the event that came before and will be coming later. I.e. events are statistically independent. The pile-up case is a single thing that one may think as an axception that, however, still may be immersed into the paradigm of statistically independent events.
Single event, including the raw and reconstructed data may entirely be kept in RAM. Typical size of event is rarely above few Mbs that is way far from the limit of modern computers capabilities.
Within the setup we distinguish various detector entities – detector assemblies, individual detectors, parts of the detectors, maintained with separate DAQ channels. Among them, the most basic detector entity is choosen with criteria that within a single event, only one measurement (hit) may be written for a unique minimal detector entity. This choosen minimal entity then becomes an important pieces of event data organization. For detailed reference, see the note about Detectors naming.
Object Model¶
In C++ the common and natural way of declaring and implementing _interfaces_ is to declare and inherit classes with virtual methods. So do we. This section describes how interfaces were defined by means of C++ classes and how they supposed to be used.
Pipeline Class¶
The pipeline is a class containing ordered list of handlers. It also offers some helper methods to iterate over imposed handlers. The implied lifecycle:
After basic application infrastructure is set up, the pipeline object is instantiated with ordered list of handlers.
Event, being read from some data source, is given to the input of the pipeline object’s helper method
Pipeline::process()which performs event propagation.At the end of processing, the pipeline is deleted with its destructor.
Note, that:
Pipeline::process()implements an iteration loop which may be abrupted, depending on special handler’s return code (see next section)Pipeline itself does not know handler of which particular type is currently being processed as well as any implementation details of the handler. All the handlers are listed by their parent type pointer (
AbstractHandler) and interface provided by this pointer is everything that pipeline needs. Such an uniformity is a standard C++ application engineering technique (it is known as levels of abstraction), so to invoke particular hndler the caller code’s abstraction layer makes no assumptions on handlers concrete type except for it has to be derived from some common base.
For simplicity, the handlers instantiation procedure is provided with one of the pipeline’s constructors because handlers composes pipeline. It is not an architectural rule – one could safely share some handler instance among multiple pipelines within a single application, albeit this use case is rarely needed.
Handler Interface¶
Each handler in NA64SW has to inherit AbstractHandler class defining basic
interface each user’s handler must to implement. The contract defined by
AbstractHandler class suggests the following lifecycle:
After basic application infrastructure is set up, the handlers are created by invoking contructors of their classes.
Event, being read from some data source, is propagated through the pipeline by sequentially invoking
AbstractHandler::process_event()method. This method may return result code of typeAbstractHandler::ProcReswhich has to be interpreted by caller code. Depending on its value the caller code may stop propagation of the current event and/or the entire event reading loop.After all events had been read, the
AbstractHandler::finalize()method is called, in order.When all handlers are “finalized”, they will be deleted with invokation of their destructors.
The role of finalize() method comes from practical need to make something
after all events have been read. Typical use case is to save file, write
resulting histogram and so on (it would be extremely inefficient to call
such procedures at each process_event() call).
Pipeline class implementation and abstract handler base class composes a bare minimum of event processing pipeline. It is pretty common, however, for practical applications to focus on subset of data related to particular detectors, and this is where a helper templated implementation of handler iterating over certain hit types becomes helpful.
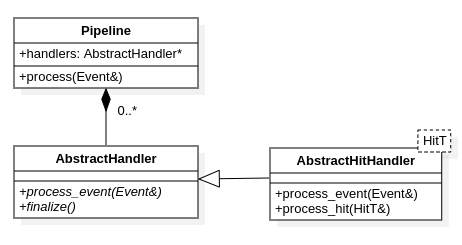
Relations between Pipeline, AbstractHandler
and AbstractHitHandler<HitT> classes.¶
The AbstractHitHandler<HitT> is parameterised with certain hit type and
provides iteration within an event by certain hit type collection.
Event object model¶
The event object comprises all the reentrant information that has to be forwarded through the handlers pipeline. To document event object model one can use UML class diagram notation.
UML Notation Basics¶
For developer convenience, events, hits and other entities are expressed by C++ types. In UML form, for instance, if one defines a C/C++ structure similar to
struct MyStruct {
float time;
int amplitude;
};
it can be drawn in UML as follows
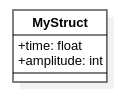
Example of class diagram for simple structure.¶
Now if we if we have, say,
a C/C++ structures called Event, SADCHit and APVHit so that
Event refers to sets (arrays or lists) of SADCHit and APVHit
instances, the UML diagram depicts it with arrows of special form.
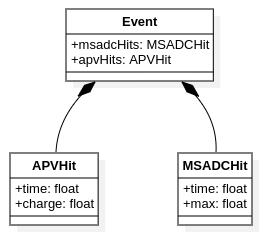
Example of Event class diagram with associations.¶
Those filled, diamond-tipped array denotes direct association implying object
ownership meaning that Event owns linked instances of SADCHit and
APVHit (if event object gets deleted, hit instances gets deleted as well).
This type of association is called composition and all the hits are contained
within the event by composition.
It is possible, however, that we would like to have entities that logically consist of hits, contained by event, but should not own the hits they refer to. Examples are clusters (thay refers to APV hits), calorimeter hits (they refer to a set of MSADC hits in individual cells), etc. Deleting cluster or calorimeter hit should not cause deletion of referred hits from lower levels and, moreover, hits can be shared among few such items. In this case we use aggregation arrow which denotes directed association without ownership.
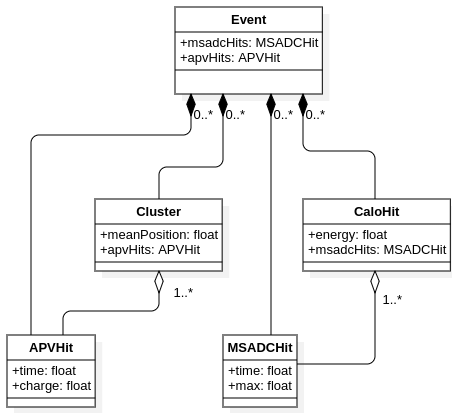
Example of Event class diagram with aggreagations.¶
UML’s goal is not to depict exactly all the details of type or relation between classes and structs, neither full list of class attributes and methods. For instance, in terms of C++ the single-object aggregation can be implemented as a pointer, reference reference or a handle with third-party ID. Arrays of objects can be vectors, lists, sets, etc and it is not necessarily must be depicted in UML as it is used to illustrate only certain aspect of the system.
Implementation Details¶
Each event object is signed by unique ID. The event ID refers to run, spill and event-in-spill identifiers. This data may be at any time utilized by handlers to e.g. access the calibration data and run meta information.
Other components of event refers to hits, clusters, track scores and tracks. This properties are created and filled dynamically by means of “events source” object assembling the event each time at the start of the event processing.
Hits are produced by triggered detector entity. By detector entity we mean what in DAQ level is a source for digit (piece of raw information) – a certain wire in tracking detector plane, a cell within a calorimeter block, etc. Each hit is signed with its unique identifier fully describing which entity had produced it.
Hit maps are the index of hits by their detector ID. Since each hit corresponds to a single detector entity, this mapping is always unique. Hit map’s only purpose is group hits by some logic criteria with an important benefit of fast look-up by the ID. One hit may be subject of multiple hit maps – e.g. the energy deposition in an electromagnetic calorimeter (ECAL) cell has to be listed in both, the SADC hits map and ECAL-only hits map. This way, handlers that operate with all the SADC or with certain (ECAL) detector’s hits will gain corresponding hits index with neglegible computational cost.
Cluster is an intermediate entity for multi-wire (and possibly pixelated) detectors that describes few spatially-adjacent entities triggered at once. This is an additional layer introduced to hold information that is not logically related to hits or track scores, but should be rather considered as a special kind of hits. See
na64dp::event::APVClusterfor instance.Track score refers to multiple hits or clusters on conjugated detector planes. See
na64dp::event::TrackScorefor details.Track point instances are grouped into Tracks that are one of the topmost entities in reconstructed event analysis.
The full structure of the event can be observed on following diagram:

To shorten the amount of utility code most of the event’s field features are expressed within the frame of C++ type traits technique.
Virtual Constructor¶
In NA64SW we use virtual constructors to instantiate objects of certain type according to run-time configuration (e.g. a configuration file).
The virtual constructor ic C++ is an idiomatic concept, pretty similar to what is called “factory constructor” (special case of more generic factory method).
Each virtual constructor defined by its abstract base class representing a family of certain subclasses. For instance, this can be an abstract event source object that simultaneously defines an interface for all the event source objects, or an abstract handler class defining an interface for all the handlers.
To automate creation of subclasses within the NA64SW framework there are few
utility programmatic entities assisting developer in an addition and choosing
the class in frame of virtual constructor. In fact, the handler’s developer may
not know what particular machinery is involving into the process of addition
of the new handler – all that must be done in order to make the system know
the new handler is to implement a body of particular class instantiation
function after the C macro REGISTER_* (e.g. REGISTER_HANDLER or
REGISTER_SOURCE) – for details, see the
Handler Developers Guide.
Internally, the virtual constructor is implemented as an associative container, indexing static functions creating particular function by their textual names. At certain moment of pipeline assembling, this container returns the particular entity-construction function providing it with runtime configuration needed by certain instance.
All the registry indexes are implemented within singletons that has a disadvantage: pipelines may not be built in parallel (but still may be ran in parallel). But it is hard to imagine this drawback would come to a trouble.